基本介紹 Data Warehouse 的設計目的與系統架構
Overview
Data Warehouse 其實也是一種資料庫, 但因為目的不一樣所以通常會與 Operational Database 分開實做, 一般來說 Data Warehouse 是為了幫助商業決策的系統, 因此有以下幾種比較明顯的特性
- 主題導向 (Subject Oriented), 會先定義主題之後才會去建立表格
- 整合性資料 (Integrated), 整合多種不同的資料來源根據主題建立表格
- 隨著時間變化 (Time Variant), 因為資料是提供歷史觀點, 所以都要定義是哪一段明確的時間區間
- 不易揮發 (Non-Volatile), 新的資料不會造成歷史資料被刪除
| OLTP (Operational Database) | OLAP (Data Warehouse) | |
|---|---|---|
| 目的 | 維持商業營運用 | 提供一般性的資料格式給內部員工使用 |
| 資料週期 | 維護資料現況 | 維護資料歷史 |
| 資料粒度 | Primitive and Highly Detail | Summarized and Consolidated |
| 資料量 | 相對少, 主要是現有資訊 | 相對多, 主要是歷史資訊且資料來源複雜 |
| 資料更新頻率 | 快 | 慢 |
| 使用者數量 | 相對多, 面向消費者 | 相對少, 面向內部員工 |
| Schema | Entity Relationship Model | Star / Snowflake / Fact Constellation |
| 架構需求 | 多工 / 備援 / 穩定 | 彈性 |
Components
Data Warehouse 並不單純只是一個 database, 它還包含周遭其他延伸的元件而形成一個系統
- Metadata: 資料的資料
- Business metadata: data ownership, business definition, changing policy
- Operational metadata: data status (active, archive, purged, …), data lineage (history logs of migrated, transform, …)
- Data for mapping from operational environment to Data Warehouse
- The algorithm for summarization
- Data Mart: 被組織過的 Data Warehouse 子集合, 只為特定一群人服務, 且都具有主題
- 經常實作在便宜的 server 上
- 通常 data mart 的實作時間都比較短, 在幾個禮拜內就可完成
- 如果沒有被組織計畫過, data mart 的生命週期很難長時間維持
- data mart 是針對部門客製化後的子集合, 可以視為是其他部門的 data warehouse
Infrastructure
個人認為根據 Data Warehouse 負責建制與維護的角色不同, 會有定義上的些許差異
以一般常見的 Three-Tier Architecture 為例, 系統架構分為 Bottom-Tier / Middle-Tier / Top-Tier
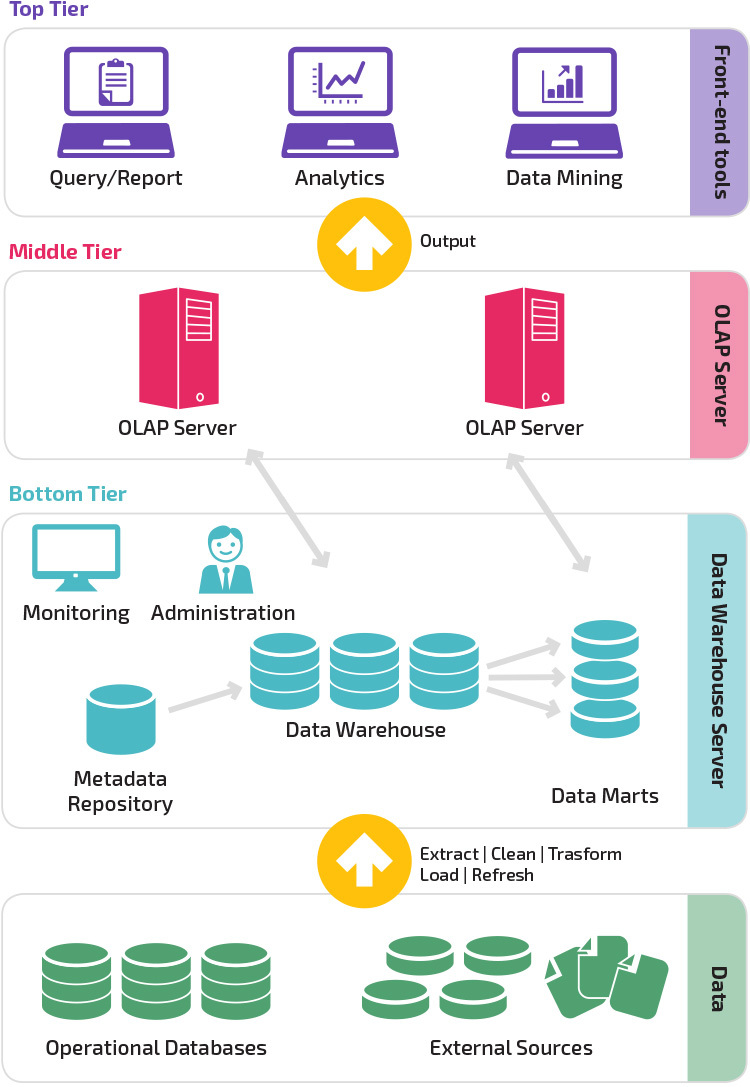
如果是比較偏向 RD 角色的人在主導 Data Warehouse 通常會把 Data Source 當作最底層 (Bottom Tier)
但如果是比較偏向資料分析角色的人主導, 在設計 Data Warehouse 的過程中比較不會討論 Operational Database, 僅僅把它當作建立過程中的 Data Source
因為我自己在公司的定位比較屬於透過 Data 幫助公司做商業決策的角色, 所以下面的討論都以商業分析維目的來討論 Data Warehouse
Three-Tier Architecture 架構設計為
- Bottom Tier (Data Warehouse Server): RDBMS
- Middle Tier (OLAP Server): 主要負責 OLAP Tools 的 requests 要轉為 SQL 查詢 DWH
- Top Tier (OLAP Tools): 前端界面
Data Warehouse Manager
當我們確立了系統架構上的分類後, 可以更仔細的來討論圍繞在 Data Warehouse Server 周遭的元件
在整個系統架構中, 會透過不同的 Manager 管理不同階段的資料處理
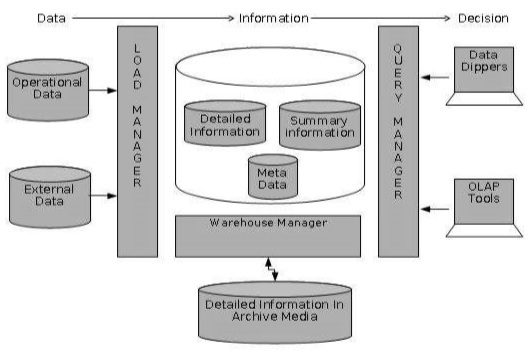
這邊我們會先撇除 Detailed Information in Archive Media 討論, 因為在前期其實大部份的時間還是會花在 ETL 跟商業邏輯的釐清, 通常等到 Data Warehouse 比較成熟後才會開始討論 Archive / Recovery / Backup 等等的策略
Load Manager
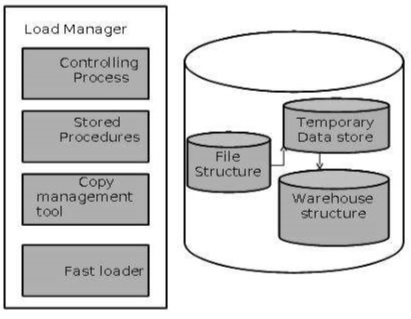
主要負責資料載入跟萃取的 Component, 因為比較接近底層, 所以通常資料內容比較接近 raw data
- 萃取資料: 從資料來源萃取資料
- 透過 Database Gateways 從 Operational Database 或是外部資料表做資料萃取 (Extraction)
- Database Gateways 替底層 DBMS 提供 SQL 界面做資料萃取
- Database Gateways e.g. Open Database Connection (ODBC), Java Database Connection (JDBC), …
- 快速載入: 快速載入被萃取後的資料進入暫存表
- Transformation 會影響資料處理的速度
- 比較有效率的作法是先把資料載入道 RDBMS 再做資料的轉換跟檢查
- 當涉及大量數據的時候, Gateways 技術並不適合使用
- 簡單轉換: 透過簡單的資料轉換與檢查, 暫存表的結構應該要接近於最後 DWH table
Warehouse Manager
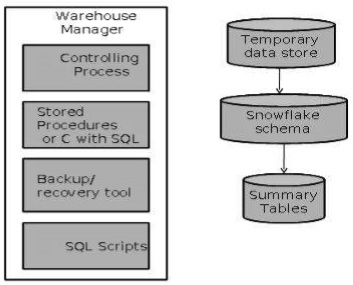
主要負責資料管理的 Component, 這邊開始包含商業邏輯, 資料內容比較偏向商業分析
- 通常需要搭配第三方系統, C, SQL, Scripts
- 操作細節
- 分析資料並執行完整性檢查
- 執行建立 indexes, business view, partition view
- 產生新的聚合資料並更新 (Generate Normalizations)
- 在 DWH 中備份資料與封存
當我們 Data Warehouse 開始要討論效能的時候通常也會從 Data Warehouse 開始著手
- 加速一般性查詢的速度
- 增加 Operational 花費
- 只要有新的資料就必須要被更新
- 不需要備份, 因為隨時可以從 detailed information 重新建立
Query Manager
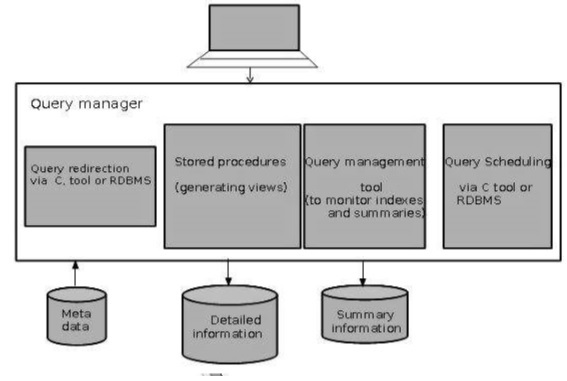
主要負責 SQL 處理過程的 Component
- 透過 C tools 或是 RDBMS 做重新導向 (SQL to table) 與排程
- 透過第三方系統做排程
- 儲存 procedure
- Query 的管理工具
Reference
- Tutorialspoint
- Fundamentals of Data Architecture to Help Data Scientists Understand Architectural Diagrams Better